A generalization of MultinomialLogisticLossLayer that takes an "information gain" (infogain) matrix specifying the "value" of all label pairs. More...
#include <infogain_loss_layer.hpp>
Public Member Functions | |
| InfogainLossLayer (const LayerParameter ¶m) | |
| virtual void | LayerSetUp (const vector< Blob< Dtype > *> &bottom, const vector< Blob< Dtype > *> &top) |
| Does layer-specific setup: your layer should implement this function as well as Reshape. More... | |
| virtual void | Reshape (const vector< Blob< Dtype > *> &bottom, const vector< Blob< Dtype > *> &top) |
| Adjust the shapes of top blobs and internal buffers to accommodate the shapes of the bottom blobs. More... | |
| virtual int | ExactNumBottomBlobs () const |
| Returns the exact number of bottom blobs required by the layer, or -1 if no exact number is required. More... | |
| virtual int | MinBottomBlobs () const |
| Returns the minimum number of bottom blobs required by the layer, or -1 if no minimum number is required. More... | |
| virtual int | MaxBottomBlobs () const |
| Returns the maximum number of bottom blobs required by the layer, or -1 if no maximum number is required. More... | |
| virtual int | ExactNumTopBlobs () const |
| Returns the exact number of top blobs required by the layer, or -1 if no exact number is required. More... | |
| virtual int | MinTopBlobs () const |
| Returns the minimum number of top blobs required by the layer, or -1 if no minimum number is required. More... | |
| virtual int | MaxTopBlobs () const |
| Returns the maximum number of top blobs required by the layer, or -1 if no maximum number is required. More... | |
| virtual const char * | type () const |
| Returns the layer type. | |
 Public Member Functions inherited from caffe::LossLayer< Dtype > Public Member Functions inherited from caffe::LossLayer< Dtype > | |
| LossLayer (const LayerParameter ¶m) | |
| virtual bool | AutoTopBlobs () const |
| For convenience and backwards compatibility, instruct the Net to automatically allocate a single top Blob for LossLayers, into which they output their singleton loss, (even if the user didn't specify one in the prototxt, etc.). | |
| virtual bool | AllowForceBackward (const int bottom_index) const |
| Public Member Functions inherited from caffe::Layer< Dtype > | |
| Layer (const LayerParameter ¶m) | |
| void | SetUp (const vector< Blob< Dtype > *> &bottom, const vector< Blob< Dtype > *> &top) |
| Implements common layer setup functionality. More... | |
| Dtype | Forward (const vector< Blob< Dtype > *> &bottom, const vector< Blob< Dtype > *> &top) |
| Given the bottom blobs, compute the top blobs and the loss. More... | |
| void | Backward (const vector< Blob< Dtype > *> &top, const vector< bool > &propagate_down, const vector< Blob< Dtype > *> &bottom) |
| Given the top blob error gradients, compute the bottom blob error gradients. More... | |
| vector< shared_ptr< Blob< Dtype > > > & | blobs () |
| Returns the vector of learnable parameter blobs. | |
| const LayerParameter & | layer_param () const |
| Returns the layer parameter. | |
| virtual void | ToProto (LayerParameter *param, bool write_diff=false) |
| Writes the layer parameter to a protocol buffer. | |
| Dtype | loss (const int top_index) const |
| Returns the scalar loss associated with a top blob at a given index. | |
| void | set_loss (const int top_index, const Dtype value) |
| Sets the loss associated with a top blob at a given index. | |
| virtual bool | EqualNumBottomTopBlobs () const |
| Returns true if the layer requires an equal number of bottom and top blobs. More... | |
| bool | param_propagate_down (const int param_id) |
| Specifies whether the layer should compute gradients w.r.t. a parameter at a particular index given by param_id. More... | |
| void | set_param_propagate_down (const int param_id, const bool value) |
| Sets whether the layer should compute gradients w.r.t. a parameter at a particular index given by param_id. | |
Protected Member Functions | |
| virtual void | Forward_cpu (const vector< Blob< Dtype > *> &bottom, const vector< Blob< Dtype > *> &top) |
| A generalization of MultinomialLogisticLossLayer that takes an "information gain" (infogain) matrix specifying the "value" of all label pairs. More... | |
| virtual void | Backward_cpu (const vector< Blob< Dtype > *> &top, const vector< bool > &propagate_down, const vector< Blob< Dtype > *> &bottom) |
| Computes the infogain loss error gradient w.r.t. the predictions. More... | |
| virtual Dtype | get_normalizer (LossParameter_NormalizationMode normalization_mode, int valid_count) |
| virtual void | sum_rows_of_H (const Blob< Dtype > *H) |
| fill sum_rows_H_ according to matrix H | |
| Protected Member Functions inherited from caffe::Layer< Dtype > | |
| virtual void | Forward_gpu (const vector< Blob< Dtype > *> &bottom, const vector< Blob< Dtype > *> &top) |
| Using the GPU device, compute the layer output. Fall back to Forward_cpu() if unavailable. | |
| virtual void | Backward_gpu (const vector< Blob< Dtype > *> &top, const vector< bool > &propagate_down, const vector< Blob< Dtype > *> &bottom) |
| Using the GPU device, compute the gradients for any parameters and for the bottom blobs if propagate_down is true. Fall back to Backward_cpu() if unavailable. | |
| virtual void | CheckBlobCounts (const vector< Blob< Dtype > *> &bottom, const vector< Blob< Dtype > *> &top) |
| void | SetLossWeights (const vector< Blob< Dtype > *> &top) |
Protected Attributes | |
| shared_ptr< Layer< Dtype > > | softmax_layer_ |
| The internal SoftmaxLayer used to map predictions to a distribution. | |
| Blob< Dtype > | prob_ |
| prob stores the output probability predictions from the SoftmaxLayer. | |
| vector< Blob< Dtype > * > | softmax_bottom_vec_ |
| bottom vector holder used in call to the underlying SoftmaxLayer::Forward | |
| vector< Blob< Dtype > * > | softmax_top_vec_ |
| top vector holder used in call to the underlying SoftmaxLayer::Forward | |
| Blob< Dtype > | infogain_ |
| Blob< Dtype > | sum_rows_H_ |
| bool | has_ignore_label_ |
| Whether to ignore instances with a certain label. | |
| int | ignore_label_ |
| The label indicating that an instance should be ignored. | |
| LossParameter_NormalizationMode | normalization_ |
| How to normalize the output loss. | |
| int | infogain_axis_ |
| int | outer_num_ |
| int | inner_num_ |
| int | num_labels_ |
| Protected Attributes inherited from caffe::Layer< Dtype > | |
| LayerParameter | layer_param_ |
| Phase | phase_ |
| vector< shared_ptr< Blob< Dtype > > > | blobs_ |
| vector< bool > | param_propagate_down_ |
| vector< Dtype > | loss_ |
Detailed Description
template<typename Dtype>
class caffe::InfogainLossLayer< Dtype >
A generalization of MultinomialLogisticLossLayer that takes an "information gain" (infogain) matrix specifying the "value" of all label pairs.
Equivalent to the MultinomialLogisticLossLayer if the infogain matrix is the identity.
- Parameters
-
bottom input Blob vector (length 2-3) 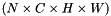 the predictions
the predictions 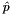 , a Blob with values in
, a Blob with values in ![$ [0, 1] $](form_102.png) indicating the predicted probability of each of the
indicating the predicted probability of each of the 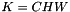 classes. Each prediction vector
classes. Each prediction vector 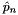 should sum to 1 as in a probability distribution:
should sum to 1 as in a probability distribution: 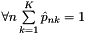 .
.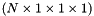 the labels
the labels 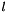 , an integer-valued Blob with values
, an integer-valued Blob with values ![$ l_n \in [0, 1, 2, ..., K - 1] $](form_24.png) indicating the correct class label among the
indicating the correct class label among the 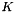 classes
classes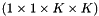 (optional) the infogain matrix
(optional) the infogain matrix 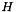 . This must be provided as the third bottom blob input if not provided as the infogain_mat in the InfogainLossParameter. If
. This must be provided as the third bottom blob input if not provided as the infogain_mat in the InfogainLossParameter. If 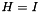 , this layer is equivalent to the MultinomialLogisticLossLayer.
, this layer is equivalent to the MultinomialLogisticLossLayer.
top output Blob vector (length 1) 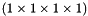 the computed infogain multinomial logistic loss:
the computed infogain multinomial logistic loss: 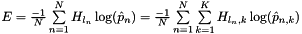 , where
, where 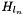 denotes row
denotes row 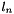 of
of 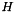 .
.
Member Function Documentation
◆ Backward_cpu()
|
protectedvirtual |
Computes the infogain loss error gradient w.r.t. the predictions.
Gradients cannot be computed with respect to the label inputs (bottom[1]), so this method ignores bottom[1] and requires !propagate_down[1], crashing if propagate_down[1] is set. (The same applies to the infogain matrix, if provided as bottom[2] rather than in the layer_param.)
- Parameters
-
top output Blob vector (length 1), providing the error gradient with respect to the outputs propagate_down see Layer::Backward. propagate_down[1] must be false as we can't compute gradients with respect to the labels (similarly for propagate_down[2] and the infogain matrix, if provided as bottom[2]) bottom input Blob vector (length 2-3) - the predictions ; Backward computes diff
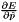
- the labels – ignored as we can't compute their error gradients
- (optional) the information gain matrix – ignored as its error gradient computation is not implemented.
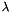 , as
, as 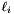 in the overall
in the overall 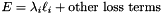 ; hence
; hence 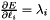 . (*Assuming that this top
. (*Assuming that this top Implements caffe::Layer< Dtype >.
◆ ExactNumBottomBlobs()
|
inlinevirtual |
Returns the exact number of bottom blobs required by the layer, or -1 if no exact number is required.
This method should be overridden to return a non-negative value if your layer expects some exact number of bottom blobs.
Reimplemented from caffe::LossLayer< Dtype >.
◆ ExactNumTopBlobs()
|
inlinevirtual |
Returns the exact number of top blobs required by the layer, or -1 if no exact number is required.
This method should be overridden to return a non-negative value if your layer expects some exact number of top blobs.
Reimplemented from caffe::LossLayer< Dtype >.
◆ Forward_cpu()
|
protectedvirtual |
A generalization of MultinomialLogisticLossLayer that takes an "information gain" (infogain) matrix specifying the "value" of all label pairs.
Equivalent to the MultinomialLogisticLossLayer if the infogain matrix is the identity.
- Parameters
-
bottom input Blob vector (length 2-3) - the predictions , a Blob with values in indicating the predicted probability of each of the classes. Each prediction vector should sum to 1 as in a probability distribution: .
- the labels , an integer-valued Blob with values indicating the correct class label among the classes
- (optional) the infogain matrix . This must be provided as the third bottom blob input if not provided as the infogain_mat in the InfogainLossParameter. If , this layer is equivalent to the MultinomialLogisticLossLayer.
top output Blob vector (length 1) - the computed infogain multinomial logistic loss: , where denotes row of .
Implements caffe::Layer< Dtype >.
◆ get_normalizer()
|
protectedvirtual |
Read the normalization mode parameter and compute the normalizer based on the blob size. If normalization_mode is VALID, the count of valid outputs will be read from valid_count, unless it is -1 in which case all outputs are assumed to be valid.
◆ LayerSetUp()
|
virtual |
Does layer-specific setup: your layer should implement this function as well as Reshape.
- Parameters
-
bottom the preshaped input blobs, whose data fields store the input data for this layer top the allocated but unshaped output blobs
This method should do one-time layer specific setup. This includes reading and processing relevent parameters from the layer_param_. Setting up the shapes of top blobs and internal buffers should be done in Reshape, which will be called before the forward pass to adjust the top blob sizes.
Reimplemented from caffe::LossLayer< Dtype >.
◆ MaxBottomBlobs()
|
inlinevirtual |
Returns the maximum number of bottom blobs required by the layer, or -1 if no maximum number is required.
This method should be overridden to return a non-negative value if your layer expects some maximum number of bottom blobs.
Reimplemented from caffe::Layer< Dtype >.
◆ MaxTopBlobs()
|
inlinevirtual |
Returns the maximum number of top blobs required by the layer, or -1 if no maximum number is required.
This method should be overridden to return a non-negative value if your layer expects some maximum number of top blobs.
Reimplemented from caffe::Layer< Dtype >.
◆ MinBottomBlobs()
|
inlinevirtual |
Returns the minimum number of bottom blobs required by the layer, or -1 if no minimum number is required.
This method should be overridden to return a non-negative value if your layer expects some minimum number of bottom blobs.
Reimplemented from caffe::Layer< Dtype >.
◆ MinTopBlobs()
|
inlinevirtual |
Returns the minimum number of top blobs required by the layer, or -1 if no minimum number is required.
This method should be overridden to return a non-negative value if your layer expects some minimum number of top blobs.
Reimplemented from caffe::Layer< Dtype >.
◆ Reshape()
|
virtual |
Adjust the shapes of top blobs and internal buffers to accommodate the shapes of the bottom blobs.
- Parameters
-
bottom the input blobs, with the requested input shapes top the top blobs, which should be reshaped as needed
This method should reshape top blobs as needed according to the shapes of the bottom (input) blobs, as well as reshaping any internal buffers and making any other necessary adjustments so that the layer can accommodate the bottom blobs.
Reimplemented from caffe::LossLayer< Dtype >.
The documentation for this class was generated from the following files:
- include/caffe/layers/infogain_loss_layer.hpp
- src/caffe/layers/infogain_loss_layer.cpp
